Product Page: https://free-addons.org
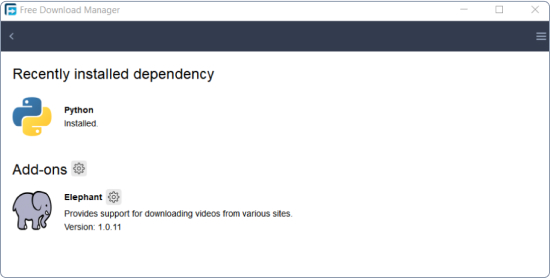
Elephant add-on for FDM (Free Download Manager) is designed to download videos from YouTube and 200+ more popular video-hosting websites.

Add-ons are extensions that can be added to a program, offering extra tools, settings, or content. They are designed to enhance the user experience and allow customization or additional capabilities beyond the default functions provided by the existing software. Add-ons are commonly used in web browsers, such as Mozilla Firefox or Google Chrome to customize users’ browsing experience, block ads, manage bookmarks, or add specific functionality like language translation or password management.
Elephant add-on for FDM built on yt-dlp. It seamlessly integrates with FDM, enabling you to download videos from YouTube and a wide range of video-hosting platforms.
– Allows you to download videos in different quality up to 4K
– Allows you to download only audio from video
– Supports MP4, WEBM, 3GP, Audio M4A, Audio WEBM and other formats
You can Download Free Download Manager for Windows and Mac here:
https://www.freedownloadmanager.org/download.htm
 <
<